Vibe check for Claude Sonnet 3.7
I wanted to drop a quick note about Claude 3.7 Sonnet. Anthropic has just released it, and it is available in both Claude and the Anthropic API.
Main features
Extended thinking
Anthropic has finally released a reasoning model. Its main feature is its toggleable reasoning mode. This means that users can toggle whether they want to receive immediate response from the model or if they want to let the model reason before answering. Anthropic calls this extended thinking. This toggle does not switch between different models, but rather it allows the very same model to give itself more time, and expend more effort, in coming to an answer.
Reasoning Budget
When using extended thinking, you can set up a token budget to control how long Claude should think for a particular question. This allows users to balance between cost and answer quality. For simpler tasks, a lower token count is usually enough, but more complex problems benefit from a higher budget. This means that if you need a quick, cheap result, you can define a low budget; but if you have a bigger problem, you can use a bigger budget.
It has a maximum of 128K tokens, though you should be aware that you will pay reasoning tokens.
This raises a very interesting tradeoff scenario, as you may want to find the right balance between optimizing results and optimizing costs. In my early testing, for simple use cases between a budget between 1 and 3K tokens is enough, but more advanced use cases may require more. Anthropic used 64K tokens for some of the benchmarks, meaning around a $1USD on reasoning tokens alone. Not all use cases may be able to afford this.
Pricing remains the same as with previous Claude 3.5 Sonnet, at $3 per million input tokens and $15 per million output tokens—which includes thinking tokens (as of Feb 25th 2025).
Visible thought process
I think Anthropic deserves extra points for showing the raw thought process. This transparency not only helps users understand how the model reasons but could also be a game-changer in fields requiring explainability. I imagine it was not an easy decision for them, but I think it aligns with their vision of transparency and explicability.
Being able to see the raw thought process opens a fascinating view into how the model reasons; how it double checks assumptions and makes the entire reasoning process more understandable for users.
It’s also worth noting that it comes with upsides and downsides:
The Good: You can use this to better understand how the model reasons about a problem, improve your prompting, and even debug issues more effectively.
The Bad: Unfortunately, the same transparency could aid bad actors in developing more advanced jailbreak techniques. As noted by Anthropic, malicious actors might be able to use the visible thought process to build better strategies to jailbreak Claude.
Anthropic even mentioned in their post that “the visible thought process in Claude 3.7 Sonnet should be considered a research preview”, and that they “will weigh the pros and cons of revealing the thought process for future releases”. So future models may not offer this.
Kudos to Anthropic for making this available!
Benchmarks
I haven’t run my own benchmarks yet, so I cannot quantitatively compare it to other models. I can say that it passes my own “vibe check” - when interacting with it and asking questions, it feels smart, snappy and responsive. So far I am a big fan of it.
Anthropic did a pretty good job documenting its results. (you can check the Appendix on their release blog.
Overall, Claude 3.7 Sonnet ranks remarkably well in software development/programming benchmarks (such as SWE-bench) and in Agentic usage (TAU Bench retail+airlines).
(all benchmark images in this post come from Anthropic’s blog).
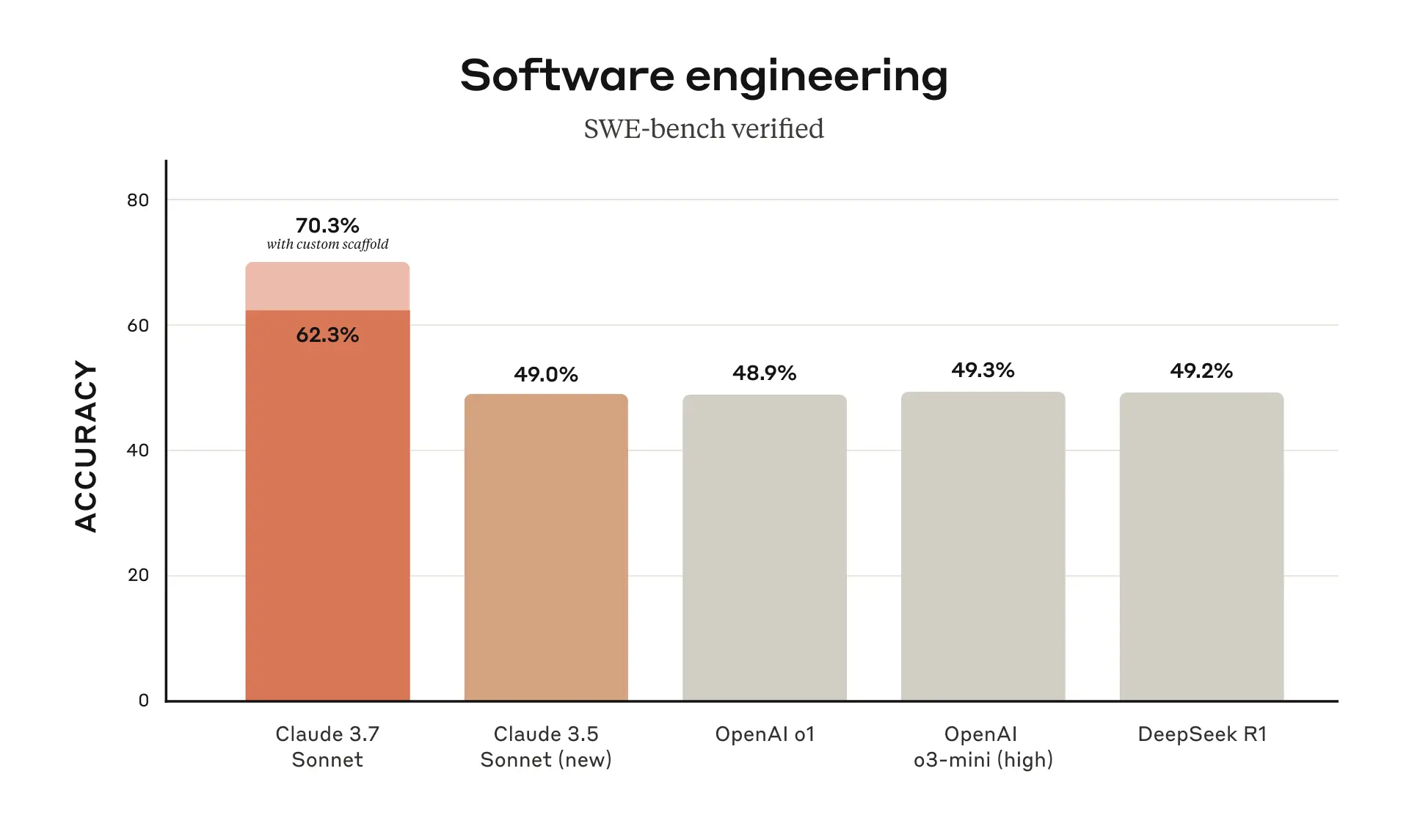
It also performs pretty well across a good number of benchmarks tailored to math and sciences, such as GPQA.
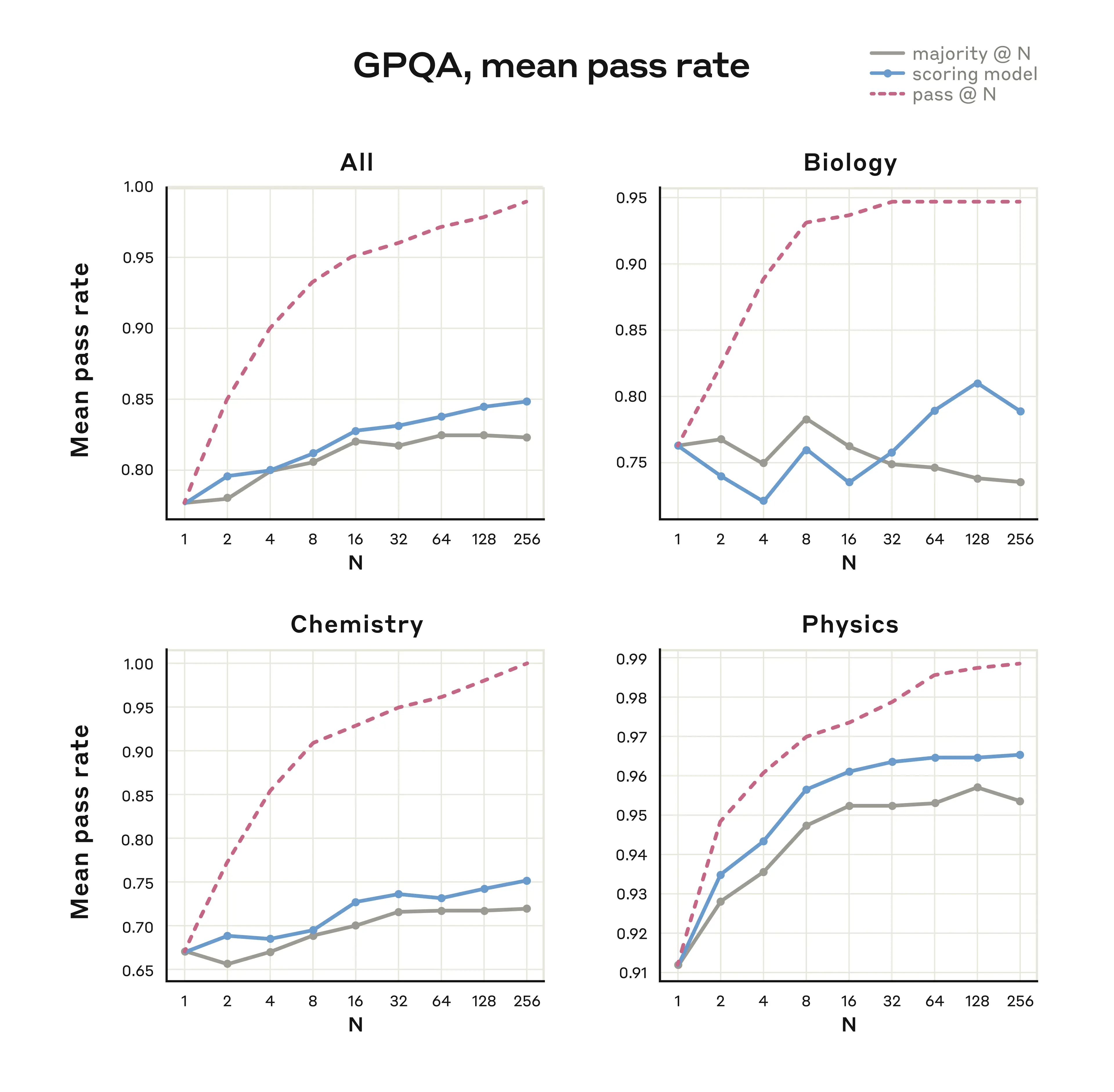
Anthropic has said:
we’ve optimized somewhat less for math and computer science competition problems, and instead shifted focus towards real-world tasks that better reflect how businesses actually use LLMs.
I think this is a great approach. I am not a big fan of this type of overly specific tests that do not necessarily translate very well into day-to-day usage.
The Pokemon Benchmark
Anthropic has developed a particularly interesting benchmark to evaluate model performance on unexpected tasks—specifically, how well they play Pokemon Red for the Gameboy🤯. While this benchmark might initially appear unconventional, it serves an important purpose in highlighting the model’s capacity for multi-step planning and strategy adaptation. These capabilities are directly transferable to complex real-world applications that require sequential decision-making and tactical adjustments.
Sonnet 3.7 was able to beat 3 gym leaders.
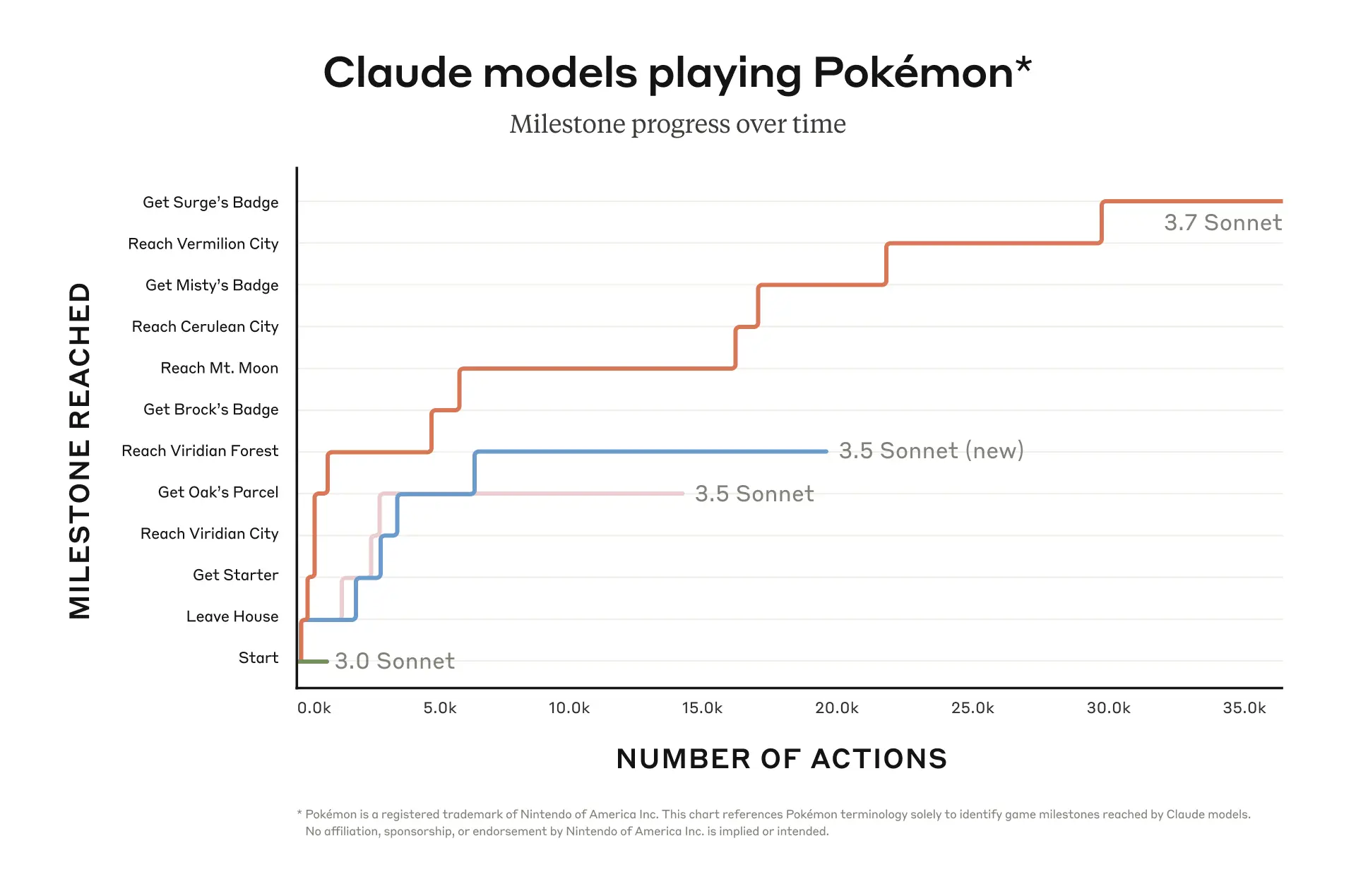
This benchmark represents a step in the right direction and away from traditional evaluation methods. I know that this might sound ironic after talking about using an LLM to play Pokemon Red, but I value the shift towards evaluating AI systems on tasks that better represent real-world challenges. I think this is precisely the kind of adaptability and strategic thinking that practical applications need.
Extra features
Parallel Test-Time Compute
On their post, Anthropic talks about a technique called “Parallel Test-Time Compute”. IT is used to improve performance on complex reasoning tasks by running multiple independent thought processes in parallel and selecting the best outcome. Instead of relying on a single chain of reasoning, this method generates several possible solutions simultaneously. These solutions are then evaluated—either through consensus methods like majority voting or by using a separate scoring model—to identify the most accurate or optimal response.
This approach is particularly useful in fields requiring high precision, such as scientific problem-solving or advanced coding tasks. It allows the model to explore different solution pathways without the linear time costs typically associated with deeper reasoning. In benchmarks like GPQA (covering biology, chemistry, and physics), Parallel Test-Time Compute significantly enhanced accuracy, with the model achieving top-tier results when scaling up to 256 parallel samples.
The core idea is that by widening the net during complex problem-solving, the model increases its chances of finding the most accurate or insightful solution—kind of like brainstorming with 256 clones of itself and picking the best answer.
Anthropic Code
Anthropic Code is a new tool introduced alongside Claude 3.7 Sonnet, designed to enhance agentic coding capabilities. It allows Claude to act as an active coding collaborator, enabling the model to not only generate code but also read, edit, run tests, and manage entire coding workflows directly through the command line. Think of it as giving Claude the ability to be a hands-on software engineer rather than just a code-suggestion tool.
In its current limited research preview, Anthropic Code can:
- Navigate complex codebases.
- Debug issues and suggest fixes.
- Refactor code at scale.
- Execute commands and interact with GitHub repositories.
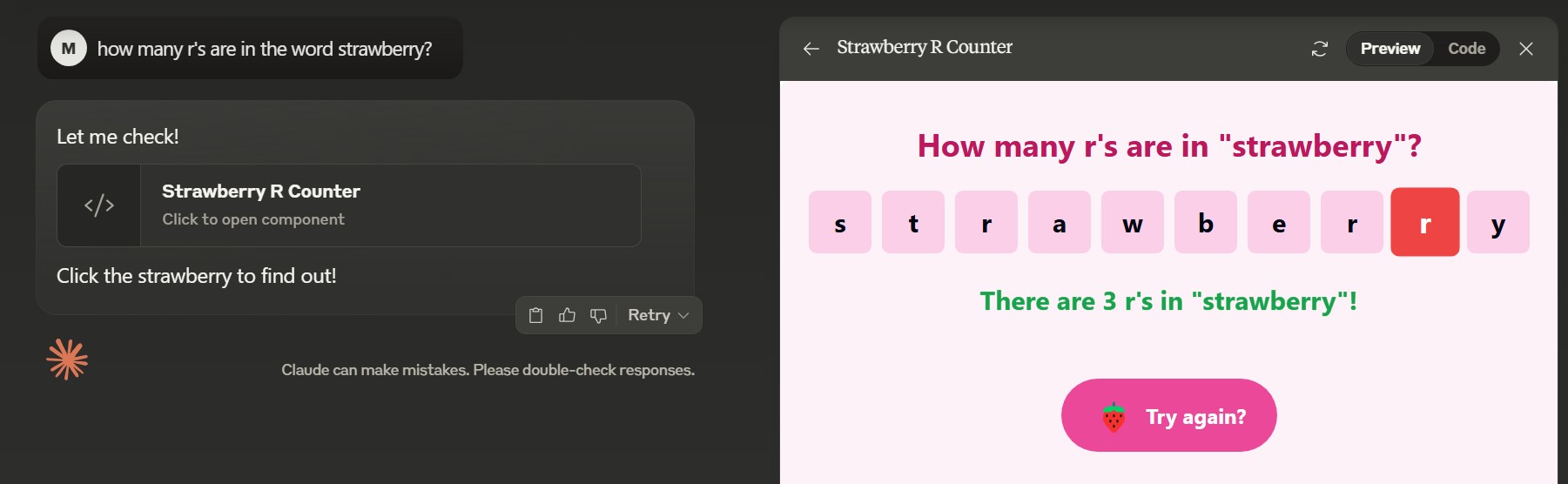
Counting r’s easter egg
It turns out there is an easter egg about the infamous “how many r’s are in strawberry”.
Final Thoughts 💡
Claude 3.7 Sonnet is a bold yet solid step forward for Anthropic—mixing transparency, control, and raw reasoning power in one single model. Extended thinking and the visible thought process offer new ways to optimize workflows and prompts, and, yes, watch an AI try to beat Pokemon Red. It also opens the door for potential jailbreaks. Anthropic’s “research preview” approach is smart—they’re testing the waters while still giving users the keys to the kingdom. I’m excited to see where they go next.